从线性变换到快速傅立叶变换(FFT) (1)
FFT(快速傅立叶变换) 是著名的算法, 将离散傅立叶变换的计算复杂度从 变为了 , 为了了解这一精妙算法, 以及其背后的对称性, 我们将从卷积出发, 从线性代数的视角看傅立叶变换是怎么自然出现, 以及其进一步利用群对称性的本质推广.
卷积是数学, 物理, 计算机等领域的常见计算需求, 在连续版本, 一维卷积的计算为
在算法上, 我们将函数变为一个向量, 实际上需要计算的是一个离散卷积
我们将从线性代数的视角审视这一变换, 固定卷积函数 , 卷积实际上在做的是将向量 变换为卷积向量 , 这满足线性变换的定义, 故这是一个在函数空间良好定义的线性变换, 我们可以使用研究线性空间的方法来研究这个变换
作为序列都是在 的意义上取
卷积作为线性变换
为了具体地研究卷积这个线性变换, 我们需要选择一组基, 不妨就直接取上面的基底(实际上就是标准正交基). 变换矩阵为
我们发现非常周期的结构, 如果提取出 的系数的话, 前三项分别是
这里 是 上的正交基, 可以看到每部分实际上都是同一个矩阵(循环矩阵)的反复作用, 记为 ,那么实际上我们有 的更简单结果
一般的卷积作用需要不断计算矩阵乘法, 如果我们能实现谱分解, 就可以让矩阵乘法变成数乘, 所以我们需要寻找 的谱分解, 不难发现 是一个 unitary matrix , 这有相当好的性质: 对于 unitary matrix , 我们知道它的特征值是单位根, 一共 n 个, 现在计算对应特征值的特征向量, 考虑单位根 , 我们有
取 , 我们发现
unitary matrix 的谱分解得到的本征向量自动是正交的, 我们取它们为一组基, 称为 Fourier basis, 把这些 basis 列在一起, 实际上就是标准基到 Fourier basis 的变换矩阵 :
即
我们看 在这一组基下的分量, 注意 是 unitary 的 (), 基变换为
每个分量恰好对应傅立叶分量. 在这个基组下, 对每个基向量的作用是数乘:
由于 , 代入谱分解即得 的对角化:
于是卷积在 Fourier 基下变为逐点乘积:
这里 是 Hadamard 乘积 (逐元素乘). 这就是时域上的卷积定理——卷积在频域中化为数乘.
这就是离散版本的卷积定理, 可以发现, 为了计算卷积, 我们需要计算傅立叶变换, 而傅立叶变换需要计算变换矩阵, 而计算消耗是矩阵乘法 , 如何减小计算消耗就是我们下面需要讨论的问题.
分治: 幂次版本
DFT 的计算消耗是 量级, 为了减小计算消耗, 我们需要利用傅立叶核的对称性, 为了能看见这一点, 我们先介绍一个简单版本, 也是算法实现上更直观的版本 — Cooley-Tukey algorithm
如果 DFT 计算的阶数 是偶数, 则 DFT 计算可以天然区分奇偶:
注意到 阶的 DFT 计算被我们变成了两个 阶的 DFT 计算, 如果 DFT 计算还有 2 的因子, 则我们可以一直做下去, 直到做到一个较小的 上我们能够直接计算 DFT 得到, 然后再递归得到整个 DFT 分量
代码实现
代码实现是简单的, 我们先给出简单的 DFT 计算程序
def DFT(x):
"""Compute the discrete Fourier Transform of the 1D array x"""
x = np.asarray(x, dtype=float)
N = x.shape[0]
n = np.arange(N)
k = n.reshape((N, 1))
M = np.exp(-2j * np.pi * k * n / N)
return np.dot(M, x)利用 numpy 的广播机制和向量化, 可以直接计算出变换矩阵, 然后递归构造 FFT
def FFT(x):
"""A recursive implementation of the 1D Cooley-Tukey FFT"""
x = np.asarray(x, dtype=float)
N = x.shape[0]
if N % 2 > 0:
raise ValueError("size of x must be a power of 2")
elif N <= 32: # this cutoff should be optimized
return DFT(x)
else:
X_even = FFT(x[::2])
X_odd = FFT(x[1::2])
factor = np.exp(-2j * np.pi * np.arange(N) / N)
return np.concatenate([X_even + factor[:N // 2] * X_odd,
X_even + factor[N // 2:] * X_odd])使用 concatenate 拼接两个小的 FFT 成分: 注意保持频率大小次序: 对原先的 k 频率成分, 合成来自两个更小的 k 成分, 注意到奇偶频率在 的意义上使用, 而外部的 factor 使用正常的 k
检查这确实符合频率成分的排序: x_even 和 x_odd 只储存了各自奇偶模式的成分, 组合为 k=0,…,n-1 种模式, 比如 1 和 N/2 +1 使用了相同的系数, 只不过是 factor 不同
向量化版本
实际上使用会直接采用向量化计算, 一次性算完需要进行的所有 DFT 计算
def FFT_vectorized(x):
"""A vectorized, non-recursive version of the Cooley-Tukey FFT"""
x = np.asarray(x, dtype=float)
N = x.shape[0]
if np.log2(N) % 1 > 0:
raise ValueError("size of x must be a power of 2")
# N_min here is equivalent to the stopping condition above,
# and should be a power of 2
N_min = min(N, 32)
# Perform an O[N^2] DFT on all length-N_min sub-problems at once
n = np.arange(N_min)
k = n[:, None]
M = np.exp(-2j * np.pi * n * k / N_min)
X = np.dot(M, x.reshape((N_min, -1)))
# build-up each level of the recursive calculation all at once
while X.shape[0] < N:
X_even = X[:, :X.shape[1] // 2]
X_odd = X[:, X.shape[1] // 2:]
factor = np.exp(-1j * np.pi * np.arange(X.shape[0])
/ X.shape[0])[:, None]
X = np.vstack([X_even + factor * X_odd,
X_even - factor * X_odd])
return X.ravel()逻辑大概为: 每一次递归产生 2 个新的 DFT 计算, 故最后递归到 时产生了 个 大小的 DFT 计算: 将需要进行 DFT 计算的向量排成列矩阵, 由变换矩阵一次性完成 DFT 计算, 然后不断拼接得到最终的频域分量即可
当然注意到这里有个结构: 在递归算法中, 我们需要的 DFT 序列不是连续的, 而 reshape 得到的每个片段是连续的向量. 实际发生的是 reshape 的矩阵, 每个列向量有 N_min 个坐标, 恰好按行数的列向量就是递归算法计算的 DFT 列向量, 变换矩阵左作用到矩阵上完成逐列向量的 DFT 变换. 故最后的每个列向量是一个 DFT 变换后的频域分量, 然后进行向上递推, 列向量是按照频率大小奇偶奇偶排列的, 然后接下来进行 vstack : 前半个频率排在上面, 后半个频率排在下面, 实现频率谱长度 x 2, 直到最后生成一个列向量, 这就是我们要的 DFT 频域向量
看起来现在我们的算法局限在处理 以及其附近的成分了, 如果 是偶数, 则我们可以开心地进行递归, 但若 不含 2 的因子, 则上述算法看似失效了? 这需要我们重新审视上面的步骤
循环群结构的分解: 混合基算法
分治的对称性
FFT 的算法只需要让我们从一个 DFT 计算中分拆出更小的 DFT 计算, 依靠递归来减小计算成本, 奇偶性只是一个我们容易拆分出更小 DFT 成分的情况, 实际发生的事情我们可以用这样一个单位根分布来表示, 图上是一个 16 阶 DFT 计算示意图, 我们每个傅立叶基表示为这样的 16 顶点
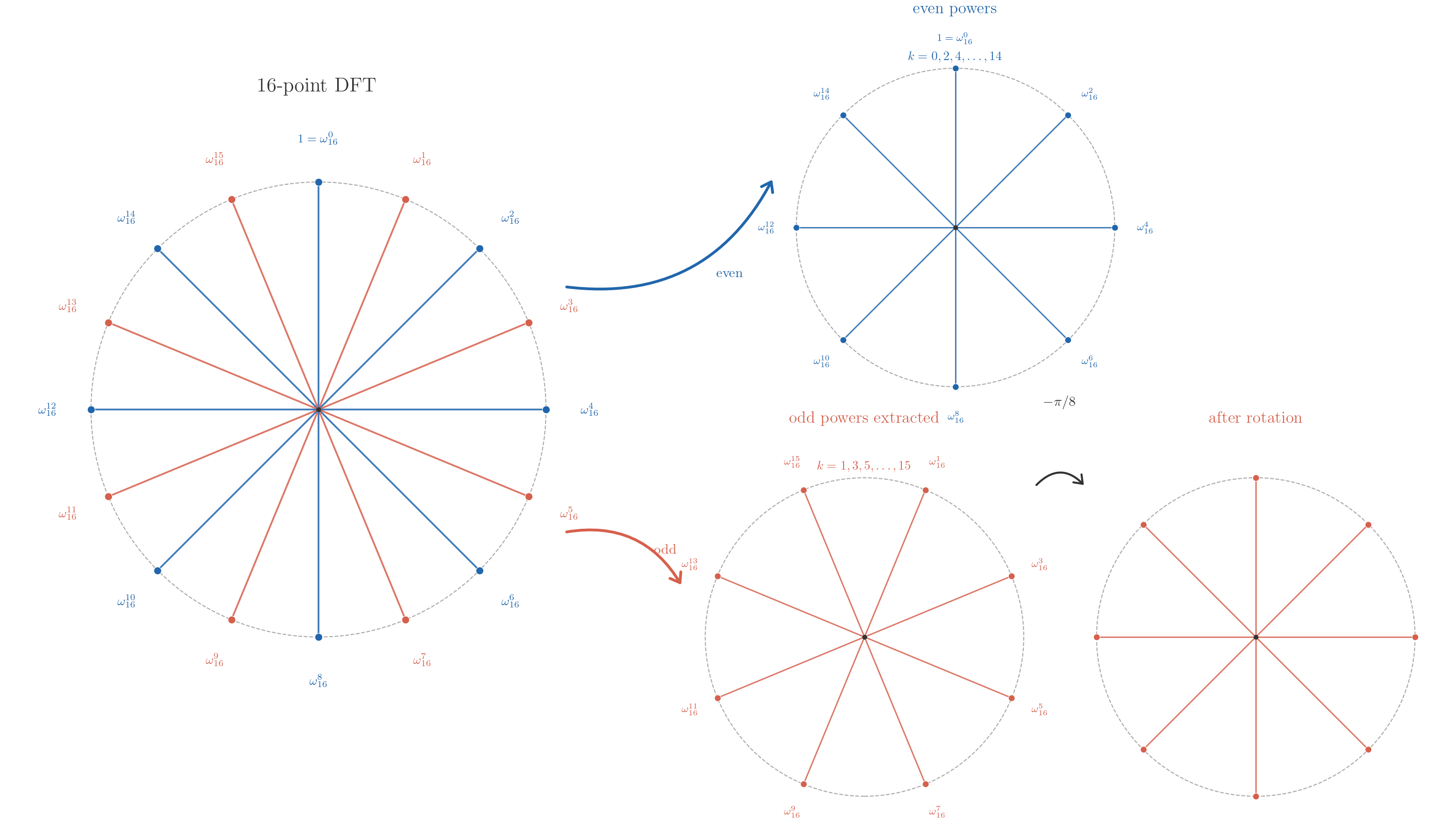
我们从这样的 16 边形中找到了两个更小周期的多边形: 8 顶点图, 正正好对应我们的奇偶性得到了两个更小规模的 DFT 计算, 所以我们发现 FFT 拆分的真正图像
能否从一个 n 顶点多边形图中, 找到更小的顶点多边形, 即找到一个更小的周期模式
我们从下面的 6 顶点图更能看出这一点
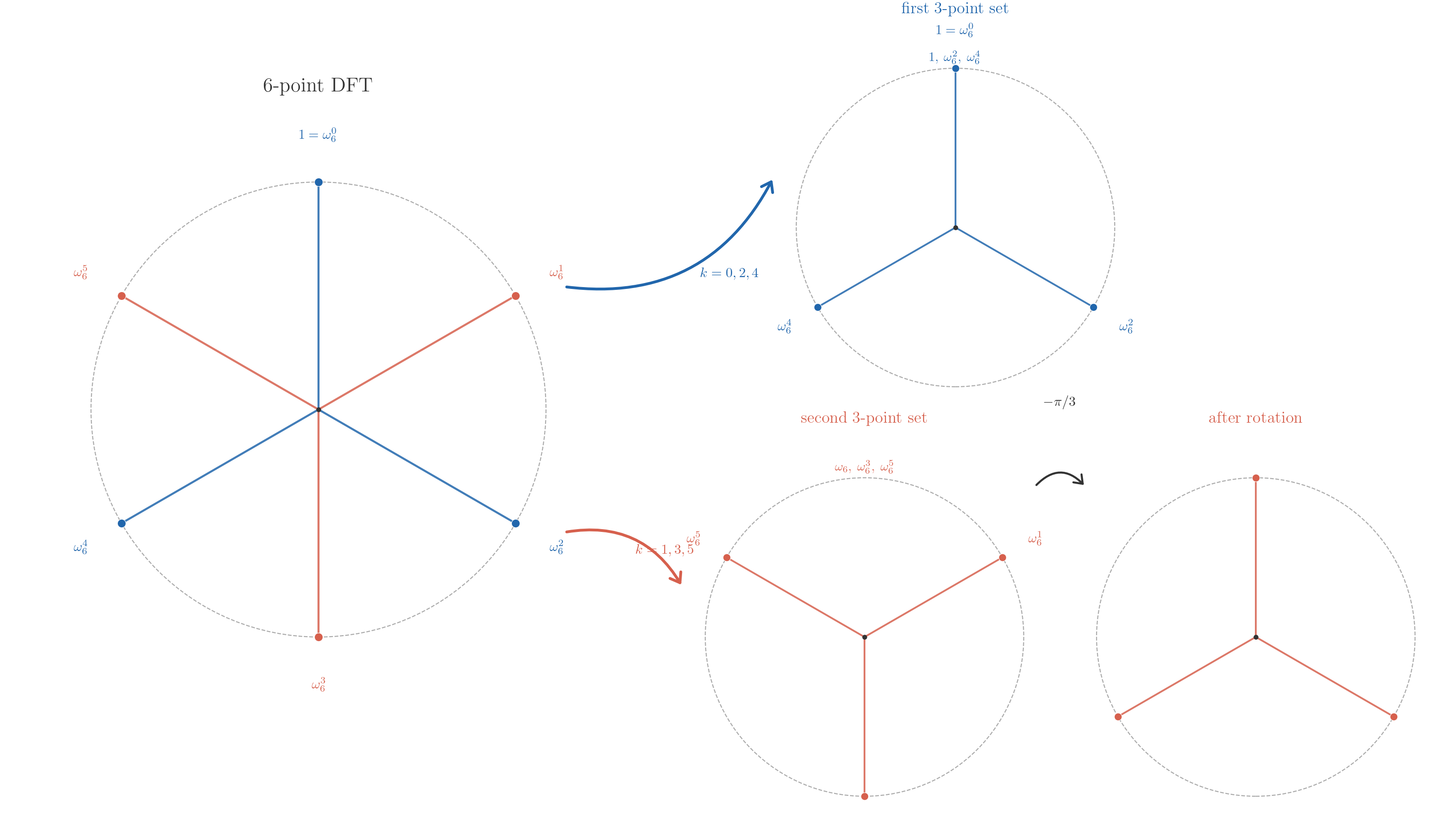
可以看见, 我们自然地从 6 顶点 DFT 中获得了两个 3 顶点 DFT , 这暗示着我们背后的群结构: 循环群的子群分解. 事实上, 循环群 对 的每个因子 恰好有一个 阶子群, 而这个子群也是循环群. 于是若 , 我们有子群 , 商群为 , FFT 的拆分正是利用了这一结构: 通过子群将 DFT 分解为更小的 DFT 计算.
当 时, 中国剩余定理给出更强的结论:
此时 DFT 矩阵可以直接分解为两个较小 DFT 的张量积, 这是混合基算法的最佳情况. 但即使不互质, 子群—商群结构已足以驱动 Cooley-Tukey 分解.
有多种方式可以证明它, 总之, 如果这个成立, 我们立刻有: 对于一个 顶点 DFT , 若 我们可以将其递归到 个 顶点 DFT 计算, 或者交换两个因子, 不难发现, 在前面的 6 顶点 DFT 中, 我们也能将其变为三个 2 顶点 DFT 计算
这就是 FFT 的混合基算法, 但是非 的素因子 DFT 向量化比较复杂, 我们这里就不再尝试代码实现
可以看到, 我们从一个计算优化问题, 先看到了奇偶自然产生的对称性, 并由此看到了背后更深的对称性, 从这个对称性出发, 我们也可以揭示 DFT 本身的对称性, 并将其推广.
不过混合基算法也是有局限的, 如果 是一个素数, 则我们仍然没有有效的分治策略, 下次我们会正式从群论角度处理这个问题, 并由此引出基于循环群本身的广义傅立叶变换.
参考资料
- Understanding the FFT — Jake Vanderplas 的 FFT 入门文章,Pythonic Perambulations,BSD 协议。本文的代码实现和分治思路受此启发
- Discrete and Fast Fourier Transform Made Clear — Peter Zeman (2019),从循环矩阵和线性代数出发推导 DFT/FFT,无需群论前置知识。与本文的数学推导视角高度一致